Project2:Hash Index
1 基本介绍
本Project将要设计一个以可扩展哈希索引实现的哈希表。
2 实验内容
2.1 Page layouts
哈希表是要通过DBMS的BufferPoolManager来访问。这意味着不能分配内存来存储信息。所有的东西都必须存储在磁盘页中,这样它们就可以从DiskManager中读/写。如果你创建了一个哈希表,把它的页面写到磁盘上,然后重新启动DBMS,应该能够在重新启动后从磁盘加载回哈希表。
为了支持在页面之上读/写哈希表桶,你将实现两个Page类来存储哈希表的数据。这是要教你如何从BufferPoolManager中分配内存作为页。
Hash Table Directory Page
此类保存哈希表的所有元数据。它分为如下表所示的字段:
| Variable Name | Size | Description |
|---|---|---|
page_id_ |
4 bytes | 该页面ID |
lsn_ |
4 bytes | 日志序列号 |
global_depth_ |
4 bytes | 目录的全局深度 |
local_depths_ |
512 bytes | 每个桶的局部深度数组(uint8) |
bucket_page_ids_ |
2048 bytes | 存储桶 page_id_t 数组 |
bucket_page_ids_ 数组将存储桶 id 映射到 page_id_t ids。 bucket_page_ids_ 中的第 i 个元素是第 i 个桶的page_id。
实现src/include/storage/page/hash_table_directory_page.h和src/storage/page/hash_table_directory_page.cpp
Hash Table Bucket Page
Hash Table Bucket Page 包含三个数组:
| Variable Name | Description |
|---|---|
occupied_ |
如果array_的第i个索引曾经被占用过,那么occupied_的第i位就是1。 |
readable_ |
如果 array_ 的第 i 个索引持有可读值,则 readable_ 的第 i 位为 1。 |
array_ |
保存键值对的数组。 |
Hash Table Bucket Page中可用的槽数取决于所存储的键和值的类型。您只需要支持固定长度的键和值。键/值的大小在单个哈希表实例中是相同的,但您不能假设它们对于所有实例都相同(例如,哈希表 #1 可以具有 32 位keys,而哈希表 #2 可以具有64 位keys)。
实现src/include/storage/page/hash_table_bucket_page.h和src/storage/page/hash_table_bucket_page.cpp。
每个 Hash Table Directory/Bucket page对应缓冲池获取的内存页的内容(即字节数组 data_)。每次尝试读取或写入页面时,您需要首先使用其唯一的 page_id 从缓冲池中获取页面,然后重新解释强制转换为目录或存储桶页面,并在任何写入或读取操作后取消固定页面。
要必须实现的唯一函数如下:
Bucket Page: - Insert - Remove - IsOccupied - IsReadable - KeyAt - ValueAt
Directory Page: - GetGlobalDepth - IncrGlobalDepth - SetLocalDepth - SetBucketPageId - GetBucketPageId
2.2 Hash Table Implementation
实现一个使用可扩展散列方案的散列表。它需要支持插入(Insert)、点搜索(GetValue)和删除(Remove)。有许多帮助函数实现或记录了可扩展哈希表的.h文件和 cpp 文件。唯一严格的 API 要求是遵守 Insert、GetValue和Remove。您还必须保留原样的 VerifyIntegrity 函数。请随意设计和实现您认为合适的附加功能。`
您的哈希表必须同时支持唯一键和非唯一键。不允许相同键的重复值。这意味着 (key_0, value_0) 和 (key_0, value_1)可以存在于同一个哈希表中,但不能存在 (key_0, value_0) 和 (key_0, value_0)。 Insert 方法仅在尝试插入现有的键值对时才返回 false。
您的哈希表实现必须隐藏键/值类型和相关比较器的详细信息,如下所示:
1 | |
这些类已经为您实现:
| Class Name | Description |
|---|---|
KeyType |
哈希表中每个键的类型。这只会是 GenericKey,GenericKey 的实际大小是使用模板参数指定和实例化的,并且取决于索引属性的数据类型。 |
ValueType |
哈希表中每个值的类型。这将只是 64 位 RID。 |
KeyComparator |
用于比较两个 KeyType实例是否小于/大于彼此的类。这些将包含在 KeyType 实现文件中。 KeyComparator 类型的变量本质上是函数;例如,给定两个键 KeyType key1 和 KeyType key2,以及一个键比较器 KeyComparator cmp,您可以通过 cmp(key1, key2) 比较键 |
请注意,可以简单地使用 == 运算符对 ValueType实例进行相等测试。
Extendible Hashing Implementation Details
此实现要求您实现存储桶拆分/合并和目录增长/收缩。可扩展散列的一些实现跳过了桶的合并,因为它可能在某些情况下导致抖动。我们在这里实现它是为了提供对数据结构的全面理解,并为学习如何管理latches、locks、page operations(获取/锁定/删除/等)提供更多机会。
目录索引
当插入你的哈希索引时,你将希望使用最小显著位来索引到目录。当然,也可以正确地使用最重要的位,但使用最不重要的位会使目录扩展操作更简单。
拆分桶
如果没有插入空间,则必须拆分存储桶。如果您发现这样更容易,您可以在桶装满后立即拆分。但是,仅当插入溢出页面时,参考解决方案才会拆分。因此,您可能会发现提供的 API 更适合这种方法。与往常一样,欢迎您考虑自己的内部 API。
合并桶
当一个桶变空时,必须尝试合并。有一些方法可以通过检查桶的占用率和它们的分割图像来更积极地进行合并,但这些昂贵的检查和额外的合并会增加激动。
为了使事情相对简单,我们提供了以下合并规则:
- 只能合并空桶。
- 只有当它们的分割图像具有相同的局部深度时,桶才能与其分割图像合并。
- 只有局部深度大于 0 的桶才能被合并。
如果您对“分割图像”感到困惑,请查看算法和代码文档。这个概念很自然地就消失了。
目录增长
这没有什么花哨的规则。您要么必须增加目录,要么不需要。
目录缩减
只有当每个桶的本地深度严格小于目录的全局深度时才会收缩目录。你可能会看到其他关于目录收缩的测试,但这个测试是微不足道的,因为我们在目录页中保留了本地深度。
Performance
一个重要的性能细节是仅在需要时才使用写锁和闩锁。总是使用写锁将不可避免地在 Gradescope 上超时。
此外,一种潜在的优化是将您自己的扫描类型考虑到存储桶页面上,这可以避免在某些情况下重复扫描。您会发现检查存储桶页面的许多内容通常涉及全面扫描,因此您可以一次性收集所有这些信息。
2.3 Concurrency Control
到此为止,你可以假设你的哈希表只支持单线程执行。在这最后一个任务中,你将修改你的实现,使其支持多线程同时读/写该表。
你需要在每个桶上设置Latch,这样当一个线程在向一个桶写东西时,其他线程就不会同时读取或修改该索引。你也应该允许多个读者在同一时间读取同一个桶。
当您需要拆分或合并存储桶以及全局深度发生变化时,您将需要锁定整个哈希表。
Requirements And Hints
Latchs
在这个项目中有两个需要注意的Latches。
第一个是extendible_hash_table.h 中的table_latch_,它在可扩展哈希表上获取锁存器。这来自src/include/common/rwlatch.h 中的 RWLatch 类。正如您在代码中看到的,它由 std::mutex支持。
第二个是 src/include/storage/page.h 中内置的页面锁定功能。这是您必须用来保护您的存储桶页面的方法。请注意,要对 table_latch_ 进行读锁定,您可以从 RWLatch.h 中调用 RLock,但要对存储桶页面进行读锁定,您必须重新解释reinterpret_cast<Page *> 到页面指针,并从页面调用 RLatch 方法。
我们建议您查看可扩展哈希表类,查看其成员,并准确分析哪些锁存器将允许哪些行为。我们还建议您对存储桶页面执行相同的操作。
项目4将通过LockManager.h中的LockManager锁定来探索并发控制。在这个项目中,你根本不需要LockManager。
事务指针
您可以在需要时简单地将 nullptr 作为事务指针参数传递。这个 Transaction 对象来自 src/include/concurrency/transaction.h。它提供了方法来存储您在遍历哈希表时获取闩锁的页面。您无需执行此操作即可通过测试。
3 实验思路
task1
该部分主要是实现Hash Directory Page和Hash Bucket Page,也就是下图左右两部分
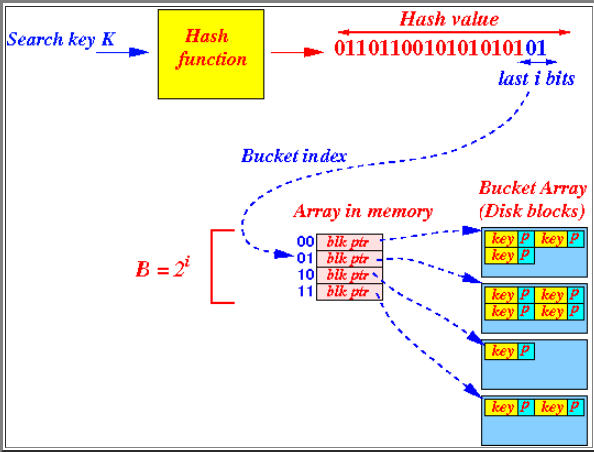
(由于经常将directory中的bucket和其指向的bucket弄混,故将directory中的称为slot,其指向的称为bucket)
hash directory page要实现的主要方法如下:
GetGlobalDepthMask:获得全局高度的mask
CanShrink:判断是否可以收缩,只有当有bucket的高度不等于global的高度时才可以
GetLocalHighBit:获得该slot指向的bucket的LHB(最低位)
GetSplitImageIndex:获得该bucket分割后的bucket对应的LHB
hash Bucket Page要实现的主要方法如下:
GetValue:获取key对应的值,直接遍历到BUCKET_ARRAY_SIZE即可
Insert:插入,插入到可读位的第一个即可
Remove:一样的,遍历到key``value相同位将readable设置即可
occupied和readable的作用
值得注意的是,该部分occupied_和readable_均为char数组,也就是说需要同个位运算来确定某个位是否可读或曾被占用。
零长度数组
在HashTableBucketPage中,保存键值对的数组是这么定义的
1 | |
这是一个Zero-length array(零长度数组)。它位于结构体/类的最后,本身不占用空间。在声明结构体的时候分配内存,去除掉其他元素的部分就是零长度数组可以访问的部分。
而类的实例化是不能定义大小的。但是,我们的类比较特殊,它的实际意义是一个页面,而页面的大小是固定的。从测试代码可以看到该类实例化是这样的:
1 | |
定义了一个页面,页面的data部分是全零的字节。使用reinterpret_cast,将这块空白解释为我们的对象。由于类中的成员函数是在代码段的,这块空白实际上被解释为类中的成员函数,内存分配与结构体类似。本题中已经根据页面大小为我们算好了BUCKET_ARRAY_SIZE,所以可以放心地取用这个零成员数组了。
Task2
该部分就是设计Extendible Hash Table了,这一块还是挺难的,难点在于split和merge方法的实现,另外,在设计时还要考虑并发性。
设计前,最好先在纸上模拟下,想好插入和删除主要流程,再动手写代码,可以参考以下两篇文章:
www.mathcs.emory.edu/~cheung/Courses/554/Syllabus/3-index/extensible-hashing-new.html
Extendible Hashing (Dynamic approach to DBMS) - GeeksforGeeks
下面来讲讲各个函数的实现思路:
初始化函数
这一块刚开始觉得好像没有什么需要初始化的,但要注意的是,我们需要初始化directory_page的id以及对应的高度才可以进行后续的操作,另外还可以初始化两个bucket
辅助性函数
找到对应的bucket index
1 | |
根据bucket_page_id得到相应的页指针和bucket_page
1 | |
查找
没什么好说,直接通过key找到对应bucket_page,在调用之前写好的GetValue即可
插入
首先获取一些数据结构,以下是经常使用的三个变量
1 | |
如果判断对应的page_data没满,直接插入即可,否则,执行SplitInsert
进入循环,首先获取常用变量old_global_depth,bucket_idx,bucket_page_id,[bucket_page, bucket_page_data]。
然后对bucket进行分割,首先检查目录是否需要增加,需要则标记。然后将bucket的深度++,调用GetSplitImageIndex得到分割bucet的LHB,然后生成split bucket。然后遍历原bucket中的可读元素,将部分元素rehash到split bucket中。
然后如果dir_page_data大小增加了,要将新增的slot指向相应的bucket。
删除
与插入操作相反,如果remove后空了,则需要进行merge操作
遍历所有bucket id,由于目录大小可能会变小,所以for中不写判断条件,当i >= dir_page_data->Size(),则break。merge时判断bucket是否为空,为空,再对split bucket深度进行判断,如果为原bucket深度,则将这两个深度–,然后将分割bucket的pageID赋给原bucket。然后遍历找到原pageID和分割pageID对应的bucketIdx,将他们的pageID都设置为分割pageID。这样操作完后,无论分割bucket还是原bucket,它们的page都是分割后的page。
4 自问自答
什么是
split image? 我的理解是split出来的bucket对应的LHB
GetLocalHighBit的作用是什么? 得到某个bucket对应的LHB
mask的作用是什么? 用于计算Hash Value后n位的(通常,n为depth的位数,例如depth为2,则mask为011)
occupied的作用是什么?