Project3:Query Execution
0 前言 & 要求
该部分是让我们实现一个执行器,从而实现以下操作:
- Access Methods: Sequential Scans, Index Scans (with your B+Tree from Project #2)
- Modifications: Inserts, Updates, Deletes
- Miscellaneous: Nested Loop Joins, Index Nested Loop Joins, Aggregation, Limit/Offset
所有的执行器采用火山模型,也就是所有的 executor 向外暴露一个 Next 接口,ExecutorEngine 通过调用 Next 接口得到一条 tuple。
一共有九个执行器。对于每种查询计划运算符类型,都有一个相应的执行器对象来实现Init和Next方法。Init方法初始化操作符的内部状态(如检索要扫表的对应表)。Next方法提供迭代器的接口,该接口在每次调用时返回一个记录和对应的RID(也可能是执行器已经结束的标志)。
对应的头文件如下:
1 | |
每个执行器负责处理单个的Plan Node类型。Plan Node是组成查询计划的各个元素。每个Plan Node可以定义他所代表的操作符的特定信息。如:顺序扫描的Plan Node必须为执行扫描的表定义标识符,而Limit的Plan Node不需要此信息。相应的Plan Node在如下文件定义:
1 | |
1 实验分析
1.1 概念
该实验的难点感觉在于有许多API,类需要自己去研究,不然很难理清执行的逻辑,下面分析一些重要的概念与流程
ExecutionEngine:用于执行查询计划,其中只有一个Execute函数。该函数逻辑不难
1 | |
ExecutorFactory:根据Node Plan去创建执行器,以下是其创建执行器的代码片段:
1 | |
Execution Plan:Executor Type Specific的创建参数(包含children、predicate、table_oid等)。对应类为AbstractPlanNode,其中主要函数与对象为:
1 | |
Execution Context:Executor Type Irrelavent的创建参数(包含各种manager、catalog等)。一般是指存储运行程序所需的上下文。以下是其中包含的对象:
1 | |
AbstractPlanNode:对SQL语句的操作进行拆分,形成一个树,其中的每一个节点就对应一个executor,而AbstractPlanNode类包含执行该节点功能需要的一些材料。该抽象类包括其子节点,以及向上返回的列格式(Schema)。
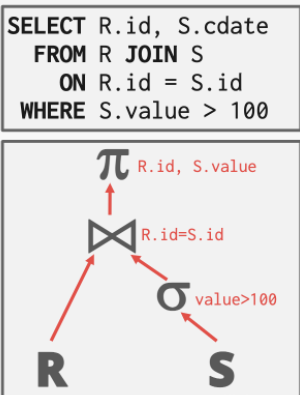
Schema:本质是Column类的集合,即一个表中的所有列。其中包含的对象为:
1 | |
Column:列。包含该column的名字、类型,以及一个Expression(optional),描述该column如何构造。其中包含的主要对象:
1 | |
Tuple:行。包含Data和RID。注意,tuple中不存储schema;TableHeap中不直接在page中保存tuple,而是保存serialize后的tuple data。以下是其中的对象:
1 | |
Value:表示一个值(Int、Char、Varchar等)。用一个Value vector和一个schema,可以构建一个tuple。
TableHeap:磁盘中的一个物理表。其中的主要对象
1 | |
TableIterator:提供对TableHeap进行顺序遍历的方法,其只存储了当前一条记录。其重载了一些基本符号,有:==, !=, ++, ->, =。存储一个当前Tuple。在取*时返回该tuple;在递增(++)时,取出该tuple中的rid,在table中定位对应的slot。然后逐slot向下遍历,直至找到下一个valid rid。
1 | |
RID:记录tuple的存储位置。包括page id+slot id。
1 | |
Expression:以树的形式递归地表示一个表达式。Expression共包含Const、Comparison、Column、Aggregation四种类型,分别用于不同的场合。
Catalog:描述着数据库内部表和索引的元数据,存储着数据库中 有哪些 table, 每个 table 的 schema 是怎么样的,每个 table 有哪些 index, index 有哪些元数据等等。以下是其中包含的两个主要对象:
1 | |
TableInfo:维护表的有关数据,其中包含的主要对象:
1
2
3
4
5
6
7
8/** The table schema */
Schema schema_;
/** The table name */
const std::string name_;
/** An owning pointer to the table heap */
std::unique_ptr<TableHeap> table_;
/** The table OID */
const table_oid_t oid_;IndexInfo:维护有关索引的元数据,其中包含的主要对象:
1
2
3
4
5
6
7
8
9
10
11
12/** The schema for the index key */
Schema key_schema_;
/** The name of the index */
std::string name_;
/** An owning pointer to the index */
std::unique_ptr<Index> index_;
/** The unique OID for the index */
index_oid_t index_oid_;
/** The name of the table on which the index is created */
std::string table_name_;
/** The size of the index key, in bytes */
const size_t key_size_;
1.2 整体逻辑
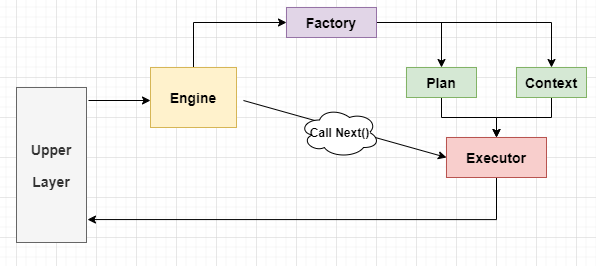
- 上层组件与Execution Engine交互。
- 在Execution Engine中,首先调用Execution Factory递归创建Executor。然后不断调用Executor的Next()方法,生成Tuple。
- 在创建Executor时,需要提供Execution Plan与Execution Context。
1.3 AbstractExpression
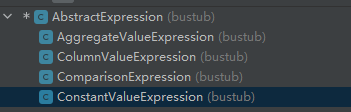
该抽象类是所有表达式的基类。它会被建模为树,即每个表达式可能有可变数量的子级。
里面主要实现的方法有以下几个:
1 | |
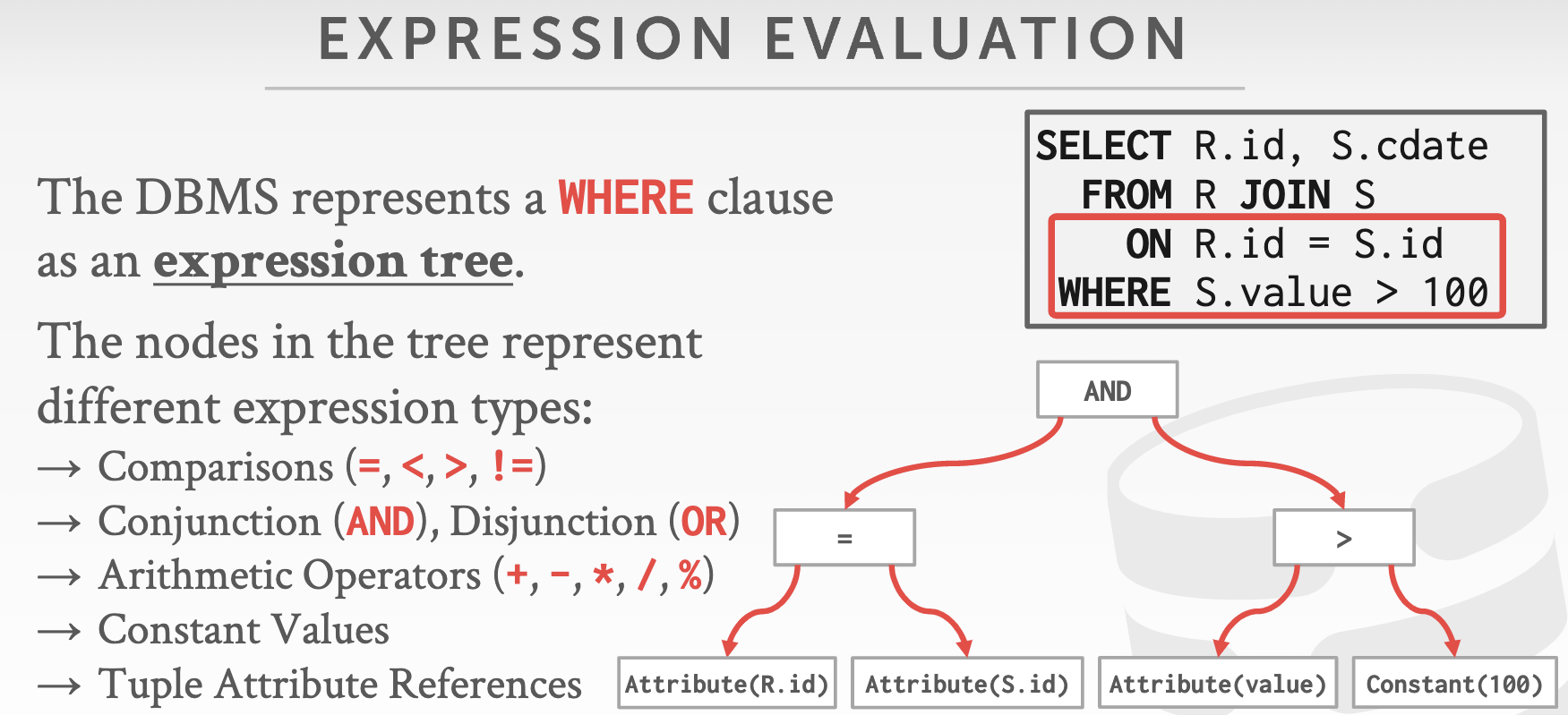
ConstantValueExpression
Evaluate()方法返回这个常量。这个Expression主要作为后面类型节点的子树。EvaluateAggregate()方法是给ComparisonExpression的EvaluateAggregate()使用的,可以不管。
ColumnValueExpression
成员变量
tuple_idx_在join操作中指明该列来自于左边的表还是右边的表,col_idx_代表该列在schema中的下标。 Evaluate()方法根据输入的tuple和schema返回tuple中该列对应的value。
EvaluateJoin()方法与前者不同的是,它接受join操作中两个表的两个tuple,根据tuple_idx_返回真正是该列对应的tuple中对应的value。
AggregateValueExpression
对应aggregate相关的列,根据类型分为group_by(分组依据)和aggregate(对该列进行取最大值等聚合操作)两种
唯一的EvaluateAggregate()方法的用途是分别传入group_by和aggregate对应的value,返回该列对应的那一个value。
ComparisonExpression
它的两个子树可能是一个
- ColumnValueExpression和一个ConstantValueExpression,Evaluate()对tuple的某列与常数比较判断大小(即WHERE)
- 两个ColumnValueExpression,EvaluateJoin()对两个tuple的两列判断是否相等(即JOIN ON)
- 一个AggregateValueExpression和一个ComparisonExpression,EvaluateAggregate()对某列aggregate的结果(或者group用到的某列)与常数比较判断大小(即HAVING)。
2 实验过程
2.1 Sequential Scan
该执行器用于顺序遍历表并一次返回一条记录。其中,SeqScanPlanNode包含将要扫描的表编号以及断言(predicate),如果某条记录不满足predicate,则不允许生成记录,相当于where。
该部分还是比较简单的,定义一个TableIterator用于遍历TableHeap。这里要注意的是:不能直接将TableIterator返回的Tuple作为输出,因为有可能plan中的out_schema仅仅只是TableHeapIterator的一个映射(意思就是可能只需要查询部分列,需要筛选出需要查询的列)。大致筛选代码如下:
1 | |
这样,再使用Tuple temp_tuple(values, output_schema);生成新的Tuple,进行判断predicate即可
2.2 Insert
InsertExecutor将记录插入表中并更新索引。这里的要求是不仅要实现原始插入(Insert into ... Values (...)),还要实现子查询插入(Insert into ... Select ...)。这里要知道的是,要通过exec_ctx_->GetCatalog()获取catalog,并调用catalog_->GetTableIndexes(table_info_->name_)得到某张表的索引。插入索引有提供好的API,直接调用即可。
另外,判断有无子计划通过plan_->IsRawInsert(),如果有,则需要模仿ExecutionEngine的Execute方法进行子执行器调用。
2.3 Update
UpdateExecutor修改指定表中的现有记录并更新其索引。挺简单,调用子查询器获得Tuple,再使用提供的API生成新元组,最后使用TableHeap中的API进行更新即可。
2.4 Delete
DeleteExecutor从表中删除记录,并从所有表的索引中删除与其有关的项。和更新差不多,根据子查询器的结果来调用TableHeap标记删除状态,然后更新索引。
2.5 Nestde Loop Join
NestedLoopJoinExecutor实现了一个基本的嵌套循环联接,他将两个子执行器中的记录组合在一起。
该执行器应实现本课程中介绍的简单嵌套循环连接算法。也就是说,对于联接的外部表中的每行记录,应考虑内部表中的每行记录。如果满足联接谓词,则应返回记录。这里的实现可以通过计算笛卡尔积并做筛选的方式。可以在Init中计算Join的结果,然后通过Next读取结果。注意使用EvaluateJoin判断两个行是否匹配。然后将匹配列输出到一个output,将每一行push到result中。在Next中返回即可。
2.6 Hash Join
HashJoinExecutor实现了一个哈希连接操作,该操作将来自其两个子执行器的记录组合在一起。顾名思义,哈希连接实在哈希表的帮助下实现的。
这里没有提供哈希方法,所以需要我们来实现,代码如下:
1 | |
同样的,依旧在Init中求出所有结果,在Next中进行返回。在遍历时,先把左表的内容散列到哈希表里,然后再遍历右表,构造结果。总体思路是先将左表中的全部列根据join条件散列到一张哈希表中,然后遍历右表,右表中的每行数据都要根据join条件的哈希结果在之前得到的哈希表中找到所有行,并一一组合。这样得到的结果才能是笛卡尔积。
2.7 Aggregation
此执行器将来自单个子执行器的多条记录的结果合并到一条记录中。这是所有执行器最难实现的一个,是基于哈希表实现的,但由于已经提供了一些API,所以只需要调用即可。通过将子查询器的数据插入到哈希表中,然后遍历时判断是否满足having条件。
2.8 Limit
LimitExecutor约束其子执行器输出的记录行数。如果其子执行器生成的记录数小于LimitPlanNode中指定的限制,则此执行器无效,并返回其接收到的所有记录。该执行器实现比较简单,保存一个计数器,然后遍历即可。
2.9 Distinct
DistinctExecutor消除从其子执行器得到的重复记录。在唯一确定的情况下,您的DistinctExecutor应该考虑输入元组的所有列。该执行器实现可以通过哈希表,也就是所有相同的行都会映射到一个相同的key,然后通过其进行去重。
测试用例除了
executor_test.cpp外,还有test/execution/executor_test_utl.h和src/catalog/table_genrator.cpp,table_generator构造一些用于测试的表。
3 自问自答
为什么不增加一个专门的Projection Executor,而是要利用output_schema来实现projection呢?
对于类似
join这种需要将中间结果存储在临时table中的复杂executor,使用output_schema能及时地进行projection操作,可以大大减少存储开销Hash Join,Sort Merge Join 的优缺点,什么时候应该用哪个?
参考
CMU15-445 Lab3 Query Execution全记录 - sun-lingyu - 博客园 (cnblogs.com)
CMU15-445 数据库实验全满分通过笔记 2021 Fall bustub-cmudb lab_twentyonepilots的博客-CSDN博客_cmu15-445