6.824 lab2:Raft
Lab2难度还是很大的,要求实现一个Raft一致性算法,主要分为了三个部分:领导选举,日志复制,持久化,日志压缩。总共花了差不多半个月完成,期间由于要准备面试,夏令营啥的耽误了些时间。在做Lab前最好先将Raft论文通读几遍,理解大概的流程,并且课程提供的locking, structure 的描述以及guidance也得好好看看,不然BUG乱飞。
0 前言 & 要求
实验代码在src/raft下,课程已经提供了大致的代码框架以及RPC代码,核心代码在raft.go中。
先说说什么是共识算法把。熟知的共识算法有两种Raft和Paxos。Raft由于其可理解性更加被大家所推崇。
而在构建分布式系统时,最基本的问题也就是:面对故障,服务器之间能否达成一致?那么,就需要共识算法来解决这一问题。通常,这种一致性通过复制日志来实现,也就是说,每个服务器存储一系列命令的日志,复制状态机顺序执行这些命令,以此保证每个每个状态机相同的状态以及输出序列(顺序性and完整性)。
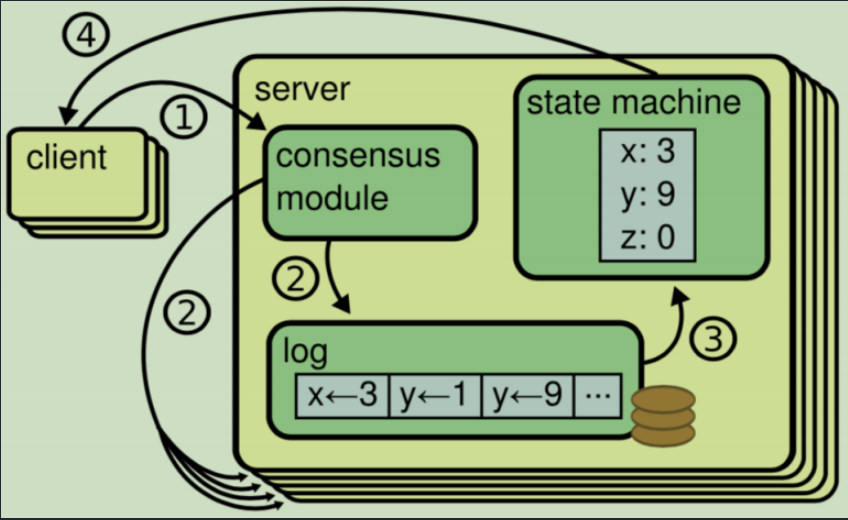
可以发现,共识算法目的其实很明显,就是为了保证日志一致性,完整性,持久性。
在Raft中,将这种一致性问题分成三个独立的子问题:
- 领导者选举:保证集群的稳定,即领导者必须存在
- 日志复制:领导者接收日志条目,并在集群复制
- 安全性:单个服务器对某个日志条目进行操作,其他服务器不可应用其他命令
这里推荐一个理解Raft算法可视化平台Raft。其实,该算法理解起来并不困难,但是当引入延迟消息,网络分区,故障服务器等,问题就不简单了,很多细节等着我们去处理。
ok,我这里只是对论文3.1之前的内容做个简述,理解问题。
1 实验分析
1.1 领导选举思路
这里分析PartA实现时的选举思路,首先,要知道每一个节点都处于三个状态之一:领导者(Leader),跟随者(Follwer),候选人(Candidate)。它们之间状态关系如下图
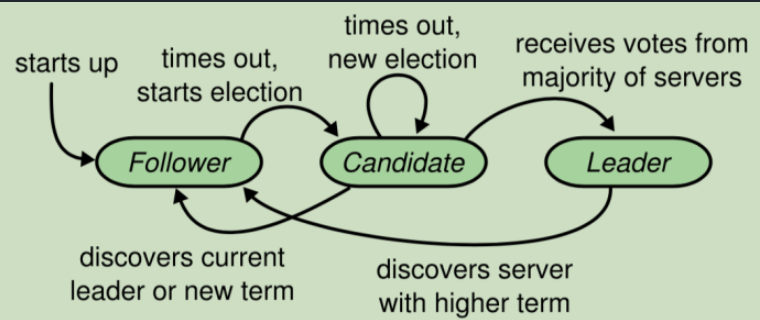
第二件要知道的是,Raft会将时间分割成任意长度的任期。如果一个候选人赢得选举,然后他就在接下来的任期内充当领导者的职责。注意,这里要保证在一个任期内,最多只有一个领导者。
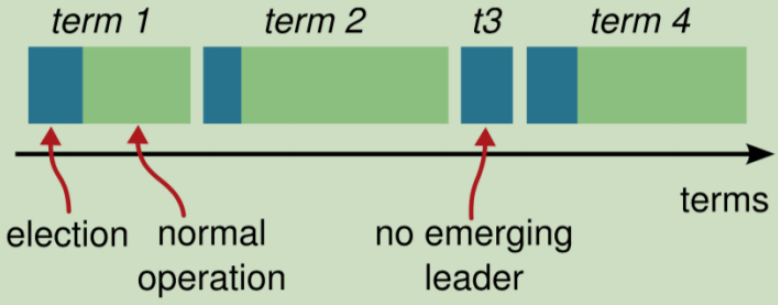
任期在选举中是十分重要的,它起到一个逻辑时钟的作用,在选举时,如果请求任期小于当前任期或者相等但当前节点已经投了别人,则需要响应拒绝;否则,将改变当前节点状态以及投票对象。并且,在Leader发送心跳时,如果小于,则说明当前Leader任期过期了,修改响应任期并返回false,否则,将Follwer的任期修改为当前Leader的任期。
ok,接下来就看看选举是怎么进行的:
首先,Follwer要先增加自己当前的任期号并转换为Candidate。然后就并行的向其他节点发送请求来给自己投票,投票结果有三种,下面逐一分析
赢得了这次的选举
一旦其赢得了选举,就会立即成为Leader,然后向其他节点发送心跳来“建立自己的权威”并且阻止新Leader的产生
其他节点成为Leader
收到了其他节点的附加日志,发现其任期要大于当前自己的任期,那么就要从Candidate转换为Follwer;否则,拒绝这次请求并保持Candidate
没有一个获胜的节点
这可能是由于选票被瓜分导致多个Follwer成为Candidate,所以,这时候每一个候选人都会超时,然后将会通过增加当前任期号来开始一轮新的选举。
如何防止选票瓜分?
使用随机选举超时时间
逻辑差不多就这样
1.2 节点之间的通信
课程已经提供了一个labrpc用于节点之间消息传递,提供的函数有一个sendRequestVote,其通过Call函数反射调用另一个Raft的方法,比如这里调用的就是RequestVote,用于处理投票响应信息。Raft中的通信类型有两种:请求投票(RequestVote)和附加条目(AppendEntries),前者由候选人选举发出,后者由领导者发出,用于复制日志以及提供心跳机制。
我将有关节点通信的类型放到rpc.go下,如下
1 | |
1.3 日志复制
日志复制是Raft算法中最核心的功能,并且也是最难实现的功能。首先,要知道的是,本地执行指令,也就是Leader应用日志到状态机这步,称作提交。然后,Leader是通过发送AppendEntries给Follwer来完成日志复制的,在此过程中,会出现以下三种情况:
Follwer没有响应Leader,那么不断重发追加条目请求(
AppendEntries RPC)即可。注意,哪怕Leader已经回复了客户端,这也说明日志已经复制给了超过半数节点,已经提交了。Follwer崩溃后恢复,这时候会执行
Raft追加条目的一致性检查,保证Follwer能够追上当前Leader。一致性检查
在
AppendEntries中,有前一个日志条目位置(PrevLogIndex)和任期号(PrevLogTerm),如果Follwer在其日志找不到前一个日志,则拒绝日志,Leader收到拒绝后,发送前一个日志条目,逐渐向前定位到Follower第一个缺失的日志。Leader宕机。那么崩溃的Leader和部分Follwer还没有提交,而被选出的新Leader又不具备这些日志,这时候就有部分Follwer的日志和新Leader的日志不相同。参照下图
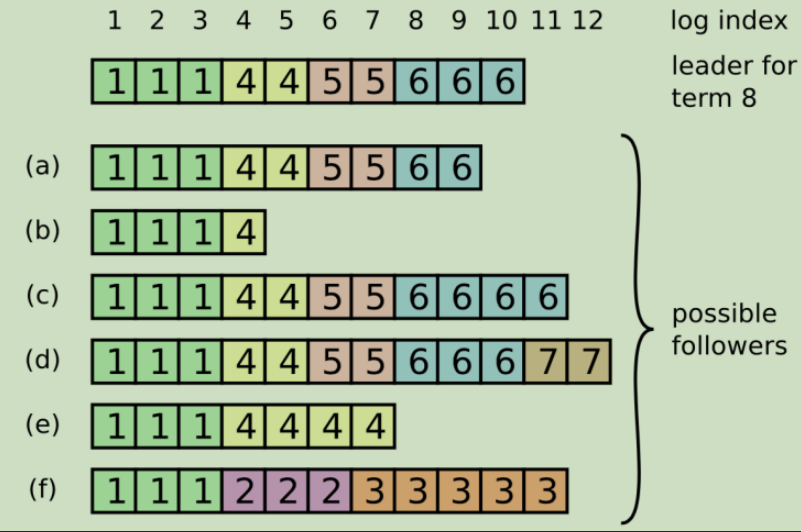
可以发现
c和d比Leader还多出两个日志,但是Leader其实还是可以通过a,b,e的投票当选,另外,f具有别的节点不具有的日志,也就是说在2,3任期担任Leader,但日志没有提交。(注:方框中数字表示该日志条目创建时的任期号) 解决方式是,Leader通过一致性检查找到Follwer中最后一个和自己一致日志之后,把这之后Follwer和自己冲突所有日志覆盖掉(因为其没有提交,抛弃也无所谓)。
1.4 安全性
领导选举+日志复制已经是Raft运行的全过程,但还不能保证状态按照顺序执行相同的命令。Raft通过补充几个规则来完善:
1. Leader宕机处理:选举限制
考虑这种情况:Follwer落后了Leader若干条日志(但没有漏掉整个任期),那么它仍然有可能当选Leader。这样它当选了之后就永远无法补上之前缺失的日志,造成状态机不一致
所以增加一个限制:保证被选出来的Leader一定包含之前各任期的所有被提交的日志条目。
解决方式:如果投票者的日志比Candidata还“新”,则拒绝投票请求。在RequestVoteReuqest中包含了最后一个日志号(LastLogIndex)以及最后一个日志任期(LastLogTerm)。如果两份日志的任期号不同,大的更“新”,相同则日志号大的更新。
2. Leader宕机处理:新Leader是否提交之前任期内的日志条目
这里是比较难理解的一部分,先看下图
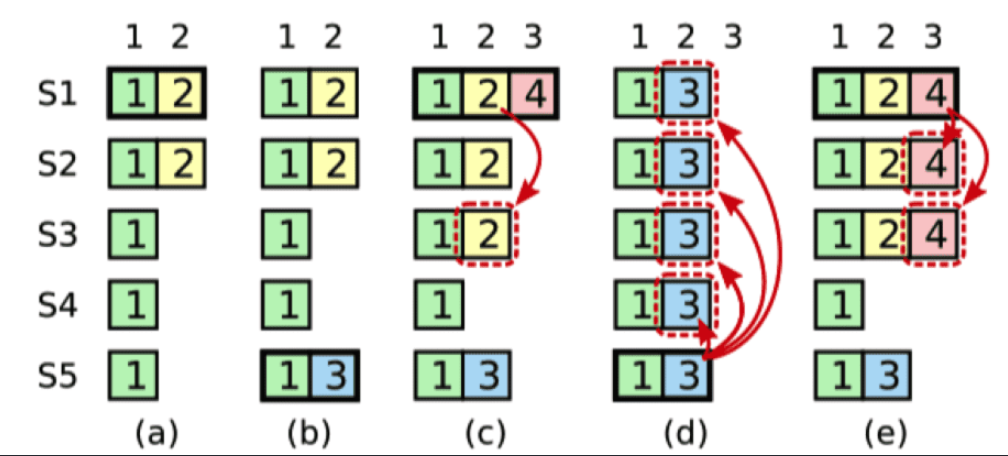
这里d和e是c处理后可能出现的两种情况,e是恰当,而d是不恰当的,下面说说
- (a):S1为Leader,复制
idx = 2的数字到S2 - (b):S1崩溃,S5上线,S5成为Leader并且
term增加到3 - (c):S5崩溃,S1恢复,然后先复制自己的
idx = 2的数据到一半以上的节点。这时候有意思的来了,会有两种情况- S1提交了
idx = 2的数据,那么会进入到d - S1不提交
idx = 2的数据,只会提交当前任期的数据,而此时当前任期(4)没有复制超过半数,所以不会提交
- S1提交了
- (d):此时S5恢复,能够赢得 S2,S3,S4 的选举,因为对于它们来说,S5 的 log 是最新的(
term最大),然后 S5 复制自己idx=2的数据到其他节点上面,可以看到原来在 S1,S2 和 S3 中idx=2committed 的数据被来自 S5 的数据(term=3)覆盖了,违背了数据一旦被 committed 就不能修改的原则。 - (e):因为
idx = 2的数据没有提交,所以即使被覆盖了也无所谓。此时S1同步了idx = 3的数据到一半的节点,因为 S1 的 term 为 4,且idx = 3,term=4的数据已经同步了一半以上的节点,可以commit,然后根据 Log Matching Property 原则,之前idx=2的数据也会被一并提交。
以上就是大概的逻辑,也解释了论文中说:只有领导者当前任期里的日志条目通过计算副本数目可以被提交。
在AppendEntriesRequest中包含了LeaderCommit用于实现这一过程,
3. Follwer和Candidate宕机处理
这里的处理方式要简单的多,两者处理方式相同,如果两者崩溃了,那么后续发送的RequestVote和AppendEntries都会失败,通过无限重试来处理着这种失败。
4. 时间与可用性限制
raft算法整体不依赖客观时间,也就是说只要整个系统满足下面的时间要求,就可以选出一个稳定的 Leader :
广播时间(broadcastTime)<< 选举超时时间(electionTimeout)<< 平均故障时间(MTBF)
1.5 日志压缩
为什么要进行日志压缩?因为不可能无限的缓存日志,日志会随着系统运行无限增加。如果某个节点下线了,然后又上线了,则这段时间同步的日志将会非常长。例如某个Follower在日志100的时候掉线了,在日志10000000的时候又重新上线了,理论上需要重传相差的日志,这不仅对带宽,对整个服务都是长时间的损耗。
测试文件
该Lab有24个测试用例,看懂测试用例很重要,不然一头雾水,对着测试用例去写准没错= =:
TestInitialElection2A:最基本的,会启动三个节点,然后检查是否存在一个Leader,过段时间再检查一次(其实让第一个节点成为Leader即可)TestReElection2A:会检测领导选举的可靠性,也就是会断开某个节点,检查是否重新选举了,还有新节点加入不会影响当前领导TestManyElections2A:同上,但节点数变多了,并且每次随机断开三个节点,再重连,检测领导选举机制的健壮性TestBasicAgree2B:最基础的追加日志测试。先使用nCommitted()检查有多少的server认为日志已经提交(在执行Start()函数之前,所有的服务器都不应该提交日志),若满足条件则调用cfg.one(),其通过调用rf.Start(cmd)来追加日志。rf.Start(cmd)用于模拟Raft实例从Client接收实例的情况。TestRPCBytes2B:基于RPC的字节数检查保证每个cmd都只对每个peer发送一次。TestFailAgree2B:断连小部分,不影响整体Raft集群的情况检测追加日志。TestFailNoAgree2B:断连过半数节点,保证无日志可以正常追加。然后又重新恢复节点,检测追加日志情况。TestConcurrentStarts2B:模拟客户端并发发送多个命令TestRejoin2B:Leader 1断连,再让旧 Leader 1 接受日志,再给新 Leader 2 发送日志,2断连,再重连旧 Leader 1 ,提交日志,再让2重连,再提交日志TestBackup2B:先给 Leader 1 发送日志,然后断连3个Follower(总共1Ledaer 4Follower),网络分区。提交大量命令给1。然后让 Leader 1 和其它Follower下线,之前的3个Follower上线,向它们发送日志。然后在对剩下的仅有3个节点的Raft集群重复上面网络分区的过程TestCount2B:检查无效的RPC个数,不能过多TestPersist12C:将节点宕机恢复验证持久化正确性TestPersist22C:验证网络分区故障的情况下持久化数据的正确性TestPersist32C:验证Leader宕机能否正确回复日志(除了所有类型节点都要在append、vote那里要持久化,Leader还有其它的地方需要持久化)TestFigure82C:Figure 8,测试paper中图8的错误情况,避免直接提交以前term的日志,其实只要知道怎么做就行了,在apply前加个判断term是否为最新的条件。TestUnreliableAgree2C:模拟不可靠网络的情况TestFigure8Unreliable2C():基于不可靠网络的图8测试TestReliableChurn2C():感觉像测试并发啥的,这里没怎么出错就没看了TestUnreliableChurn2C():同上
2 实验过程
2.1 Part 2A: leader election
第一部分实现领导选举的功能,不难,参照论文的Figure 2去做,并且这一部分也有许多可视化的网站(Raft Consensus Algorithm),理解起来并不难。
如果认真看过测试用例,可以发现程序入口其实是Make函数,它其中又启动了一个守护线程tricker,不停的运行,我的实现是里面会有一个协程定期收到两个 timer 的到期事件,如果是 election timer 到期,则发起一轮选举;如果是 heartbeat timer 到期且节点是 leader,则发起一轮心跳。
1 | |
2.2 Part 2B: log
这部分才是真滴难,我们要完成日志复制以及日志同步的一系列代码,如果你在做这部分,可能会被许多不同index搞得晕头转向,困扰于apply,commit,replite等概念,不知道什么时候进行复制,什么时候进行提交,即使看了论文也不知道如何下手等等。下面我会把我刚开始疑惑的问题列出并分析
一些变量的解释
由Leader来维护
nextIndex[]:表示需要发给每个Follwer的下一个日志条目的索引(初始化为 Leader 最新log的index+1,因为Leader总是先假定所有的follower和自己是一致的,后面说明当有不一致的时候是如何协商的)
matchIndex[]:表示已经复制到每个follower的log的最高index值(从0开始递增)
这里刚开始挺纳闷的,这不是就是matchIndex = nextIndex - 1,为啥设置两个= =。看了Guide和些博文知道,nextIndex一般都是乐观的,比如说一个Leader刚被选出来,它的nextIndex可能会全是7(因为它认为自己有的,其他节点肯定也有)。而matchIndex通常是保守的,这是follwer和Leader“协商”好的共同日志。
我想这样做的目的是为了提高性能,因为通常来说节点都已经存在一些日志,出现丢失和多出的概率不高,nextIndex可以帮助快速定位节点已有日志。
加速日志回溯优化
这概念论文中没有说,但在Guide里面提了,也就是对一致性检查和冲突日志检查的优化。
首先,要在AppendEntriesResponse增加两个字段ConflictIndex和ConflictTerm。
- 如果一个follower在日志中没有
prevLogIndex,应该返回conflictIndex=len(log)和conflictTerm = -1。 - 如果一个follower在日志中有
prevLogIndex,但是term不匹配,它应该返回conflictTerm = log[prevLogIndex].Term,并且查询它的日志以找到第一个term等于conflictTerm的条目的index。
通过上述处理返回conflictTerm 和conflictIndex,再进行如下判断
- 一旦收到一个冲突的响应,leader应该首先查询其日志以找到
conflictTerm。如果它发现日志中的一个具有该term的条目,它应该设置nextIndex为日志中该term内的最后一个条目的索引后面的一个。 - 如果它没有找到该term内的一个条目,它应该设置
nextIndex=conflictIndex。
这里参照本文1.3的图去理解。例如,使用这种方法图中(f)可以快速越过term=3的所有日志条目,下次再请求跳过term=2的,而不是如论文中每次跳过一个日志条目。
commit和apply
日志复制之后对于Leader和Follwer根据不同情况要进行提交。其中涉及两个重要字段是LeaderCommit和commitIndex
对于Leader:
如果有半数以上的复制的日志条目Index大于当前提交日志条目,并且Index小于等于最后一个日志条目索引和term相等,则提交
对于Follwer:
如果leaderCommit大于commitIndex,则设置commitIndex为Min(leaderCommit, rf.getLastLog().Index)。
提交后,还需要进行apply
Leader apply一个log entry到state machine以后,会通知该channel;这样,client只需要通过监控applyCh是否有更新即可知道是否command已commit成功。当lastApplied < commitIndex进行apply
异步
replicator
每个 peer 在启动时会为除自己之外的每个 peer 都分配一个 replicator 协程。对于 follower 节点,该协程利用条件变量执行 wait 来避免耗费 cpu,并等待变成 Leader 时再被唤醒;对于 leader节点,该协程负责尽最大地努力去向对应 Follower 发送日志使其同步,直到该节点不再是 leader或者该 follower节点的 matchIndex 大于等于本地的 lastIndex。
如果不这样做,使用传统的方法:无论心跳超时还是上层服务传来一个command,都会发起一次RPC调用。这是很浪费资源的。通过上述实现,可以减少发送重复entry导致的日志同步次数以及RPC调用次数。同时,可以实现多个节点并行复制。
1 | |
applier
这是用于apply,触发方式有两种
- Leader提交了新的日志
- Follwer通过Leader发来的
LeaderCommit来更新CommitIndex
这里用一个applier 协程,让其不断的把 [lastApplied + 1, commitIndex] 区间的日志 push 到 applyCh 中去。
通过这样做,可以为每次push操作都加上锁,这样在push结束后,lastApplied就会被及时的修改,而防止提交重复entry的情况。并且也可以使得日志 apply 到状态机和 raft 提交新日志可以真正的并行
需要注意的是:修改lastApplied要使用apply applych前的commitIndex而不是rf.commitIndex,因为后者有可能在下一次提交被修改了
1 | |
2.3 Part 2C: persistence
该部分代码实现比较简单,但如果之前PartB没写好,这里就会会发现很多问题。论文中指出要持久化的东西是:currentTerm, voteFor 和 logs[]。即实现persist和readPersist。
持久化的时机就是:哪里对logs[],votedFor,currtentTerm 进行了修改,那么哪里就需要持久化数据。
其实这里是结合PartB进行优化的,但我将优化放到前面说了,通常在加入持久化后会发现很多bug,然后需要一步步优化。
1 | |
2.4 Part 2D: log compaction
需要实现以下三个方法:
Snapshot(index int, snapshot []byte):应用程序将index(包括)之前的所有日志都打包为了快照,即参数snapshot [] byte。在函数中要做的就是,将打包为快照的日志直接删除,并且要将快照保存起来,因为将来可能会发现某些节点大幅度落后于 Leader 的日志,那么 Leader 就直接发送快照给它,让他的日志“跟上来”。
1 | |
CondInstallSnapshot(lastIncludedTerm int, lastIncludedIndex int, snapshot []byte) bool:如果一个节点接收到一个快照后,提交给上层应用(由InstallSnapshot来完成这个工作),上层应用必须要判断,目前接收到的快照是不是有效的,如果快照的lastIncludedIndex比自己的最后一个日志的log entry index要大,那也就是说自己的日志太落后,要更新下。如果收到老的快照,那么就直接丢弃。
1 | |
InstallSnapshot(request *InstallSnapshotRequest, response *InstallSnapshotResponse):RPC处理函数,每一个节点在这个处理函数中接收来自 Leader的快照,然后要判断一下是不是过期的快照。不然的话就直接传给上层应用,让它去判断是否要应用快照里面的内容。 在lab中,往applyCh写入一个snapshot就是将快照传给应用的过程。 (解释下“过期”:
request.LastIncludedIndex <= rf.commitIndex,说明本地已经包含了该 snapshot 所有的数据信息,尽管可能状态机还没有这个 snapshot 新,即 lastApplied 还没更新到 commitIndex,但是 applier 协程也一定尝试在 apply 了,此时便没必要再去用 snapshot 更换状态机了)
1 | |
3 总结
该部分复现了论文中Raft算法,整体难度很高,看了许多文章以及别人的优化才得以完成,收获还是很大的。
可以看出,共识算法是围绕着集群管理备份日志这一目标而实现,使得一个集群对外表现的像单台机器一样,对内提供容错,日志同步等。这也保证一个系统的可靠性。
简单来说,raft是一个实现强一致性的共识算法,为了容易理解,作者将其拆分成了Leader选举、日志备份、安全性三个部分。它的可靠性离不开选举算法的可靠性,通过选出Leader来帮助进行集群的日志同步,实现快照,KV层写处理等。对于日志同步来说,要尽量保证一个follower的log不落后于Leader,就要通过Leader定时发送AE,来帮助Follower“跟上来”。但是,Raft有一条规则:Leader只能提交自己拥有的Log。这是为了防止老Leader覆盖已提交的Leader造成系统不正确。持久化的策略很简单,涉及到log,votefor,currentTerm的修改都进行提交。对于日志压缩,这是提供给上层应用程序的一个功能,当上层程序调用制作快照的方法,意味着commitIndex之前的log都不需要保留了,这大大减少了因保存大量日志对服务器的负担。